Rozpoznawanie tekstu w pliku PDF online.
Nie zawsze możliwe jest wyodrębnienie tekstu z pliku PDF za pomocą konwencjonalnego kopiowania. Często stronami takich dokumentów są zeskanowane treści ich papierowych wersji. Aby przekonwertować takie pliki na w pełni edytowalne dane tekstowe, używane są specjalne programy z funkcją optycznego rozpoznawania znaków (OCR).
Takie rozwiązania są bardzo trudne do wdrożenia, a zatem kosztują dużo pieniędzy. Jeśli chcesz regularnie rozpoznawać tekst w formacie PDF, zaleca się zakup odpowiedniego programu. W rzadkich przypadkach bardziej logiczne byłoby korzystanie z jednej z dostępnych usług online o podobnych funkcjach.
Treść
Jak rozpoznać tekst z pliku PDF online
Oczywiście zestaw funkcji usług internetowych OCR jest bardziej ograniczony w porównaniu do pełnych rozwiązań komputerowych. Ale możesz pracować z takimi zasobami za darmo lub za symboliczną opłatą. Najważniejsze jest to, że odpowiednie aplikacje internetowe radzą sobie również z głównym zadaniem, jakim jest rozpoznawanie tekstu.
Metoda 1: ABBYY FineReader Online
Firma zajmująca się rozwojem usług jest jednym z liderów w dziedzinie optycznego rozpoznawania dokumentów. ABBYY FineReader dla Windows i Mac to wydajne rozwiązanie do konwersji plików PDF na tekst i dalszej pracy z nim.
Internetowy odpowiednik programu jest oczywiście gorszy od funkcjonalności. Mimo to usługa może rozpoznać tekst ze skanów i zdjęć w ponad 190 językach. Obsługuje konwersję plików PDF do dokumentów Słowo , Excel itp.
Usługa online ABBYY FineReader Online
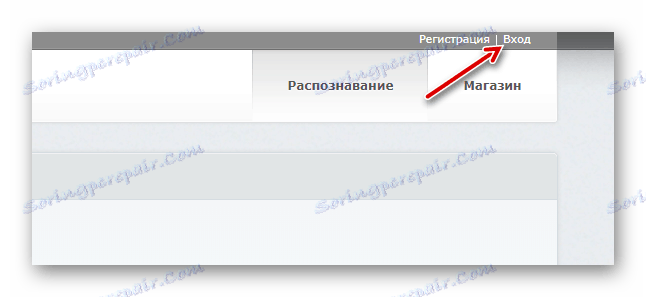
- Zanim zaczniesz pracę z narzędziem, utwórz konto na stronie lub zaloguj się przy użyciu konta Facebook, Google lub Microsoft.
![Zarejestruj się w ABBYY FineReader Online]()
Aby przejść do okna logowania, kliknij przycisk "Zaloguj się" w górnym pasku menu. - Po zalogowaniu, zaimportuj żądany dokument PDF do programu FineReader za pomocą przycisku "Prześlij pliki" .
![Rozpoznawanie tekstu z dokumentu PDF w usłudze online ABBYY FineReader Online]()
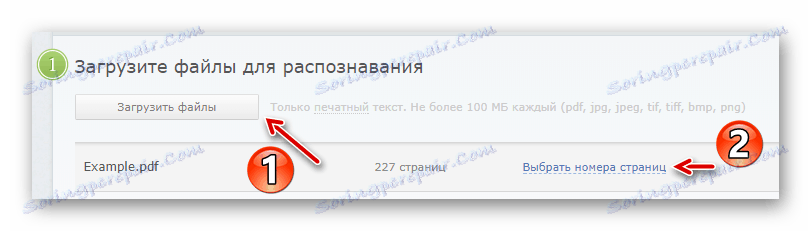
Następnie kliknij "Wybierz numery stron" i określ żądany interwał rozpoznawania tekstu. - Następnie wybierz języki obecne w dokumencie, format pliku wynikowego i kliknij przycisk "Rozpoznanie" .
![Rozpocznij rozpoznawanie tekstu z dokumentu PDF w programie ABBYY FineReader Online]()
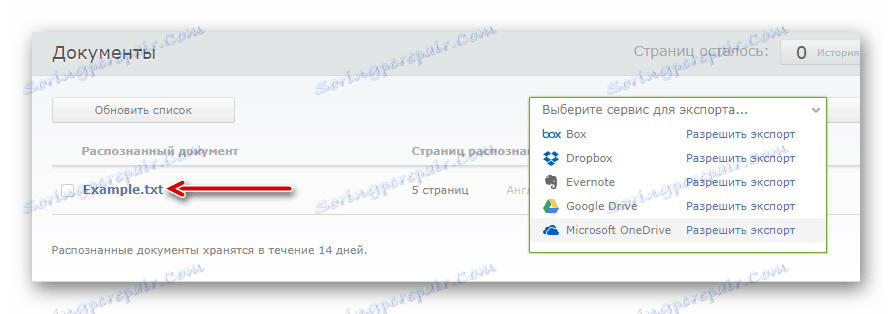
- Po przetworzeniu, którego czas trwania zależy całkowicie od wielkości dokumentu, można pobrać gotowy plik z danymi tekstowymi, po prostu klikając jego nazwę.
![Pobieranie gotowego dokumentu z usługi online ABBYY FineReader Online]()
Lub wyeksportuj go do jednej z dostępnych usług w chmurze.

Usługa wyróżnia się prawdopodobnie najdokładniejszymi algorytmami rozpoznawania tekstu na obrazach i plikach PDF. Niestety jego bezpłatne wykorzystanie ogranicza się do pięciu stron przetwarzanych miesięcznie. Aby pracować z większą ilością dokumentów, musisz wykupić roczną subskrypcję.
Jeśli jednak funkcja OCR jest bardzo rzadko potrzebna, program ABBYY FineReader Online jest świetną opcją do wyodrębniania tekstu z małych plików PDF.
Metoda 2: Bezpłatne Online OCR
Prosta i wygodna usługa digitalizacji tekstu. Bez konieczności rejestracji, zasób umożliwia rozpoznanie 15 pełnych stron PDF na godzinę. Bezpłatne Online OCR w pełni działa z dokumentami w 46 językach i bez autoryzacji obsługuje trzy formaty eksportu tekstu - DOCX, XLSX i TXT.
Podczas rejestracji użytkownik może przetwarzać dokumenty wielostronicowe, ale liczba tych stron jest ograniczona do 50 jednostek.
Usługa online Bezpłatne Online OCR
- Aby rozpoznać tekst z pliku PDF jako "gość", bez upoważnienia do zasobu, użyj odpowiedniego formularza na głównej stronie witryny.
![Rozpoznawanie PDF w usłudze online OCR Bezpłatne Online]()
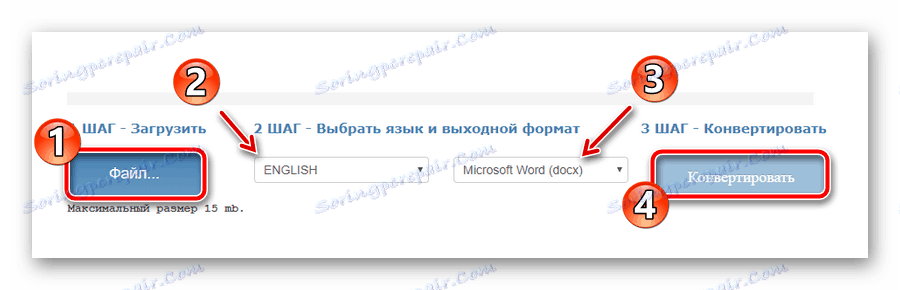
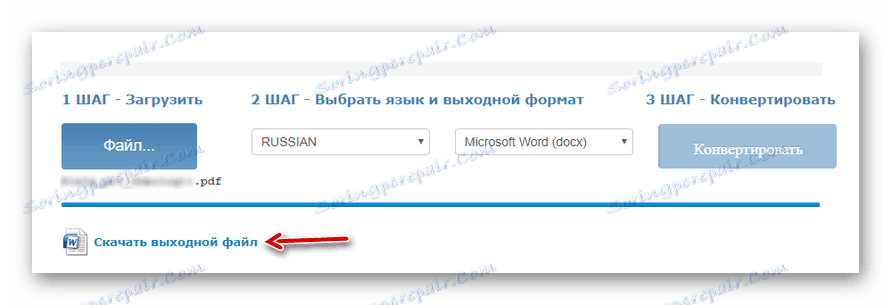
Wybierz żądany dokument za pomocą przycisku "Plik" , wybierz główny język tekstowy, format wyjściowy, poczekaj na pobranie pliku i kliknij "Konwertuj" . - Po zakończeniu procesu digitalizacji kliknij "Pobierz plik wyjściowy", aby zapisać gotowy dokument wraz z tekstem na komputerze.
![Pobieranie wyników rozpoznawania tekstu z pliku PDF z usługi online OCR online]()
Dla autoryzowanych użytkowników kolejność działań jest nieco inna.
- Użyj przycisku "Zarejestruj się" lub "Zaloguj się" na górnym pasku menu, aby odpowiednio utworzyć lub uzyskać dostęp do swojego konta OCR online.
![Tworzenie konta w usłudze online Bezpłatne Online OCR]()
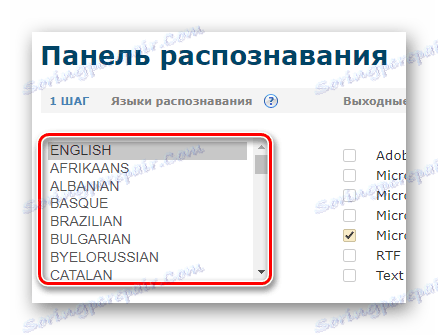
- Po autoryzacji w panelu rozpoznawania przytrzymaj klawisz "CTRL" i wybierz maksymalnie dwa języki dokumentu źródłowego z dostarczonej listy.
![Określanie języków dokumentu źródłowego dla rozpoznawania tekstu w Free Online OCR]()
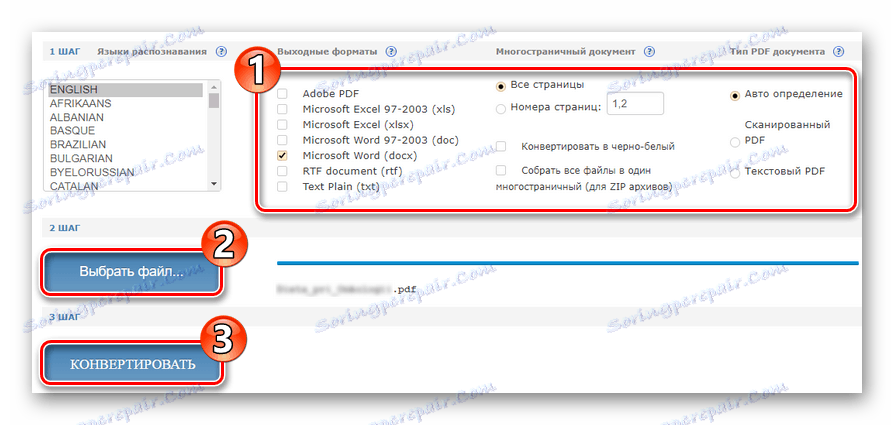
- Określ dalsze parametry dla wyodrębniania tekstu z pliku PDF i kliknij przycisk "Wybierz plik" , aby przesłać dokument do usługi.
![Rozpoczęcie rozpoznawania dokumentu PDF w internetowej usłudze online OCR]()
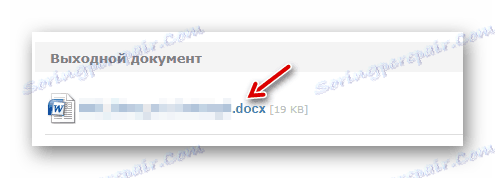
Następnie, aby rozpocząć rozpoznawanie, kliknij "Konwertuj" . - Po przetworzeniu dokumentu kliknij łącze z nazwą pliku wyjściowego w odpowiedniej kolumnie.
![Pobieranie gotowego pliku DOCX z internetowej usługi Online OCR]()
Wynik rozpoznania zostanie natychmiast zapisany w pamięci komputera.
Jeśli chcesz wyodrębnić tekst z małego dokumentu PDF, możesz bezpiecznie skorzystać z narzędzia opisanego powyżej. Aby pracować z dużymi plikami, będziesz musiał kupić dodatkowe symbole w Free Online OCR lub skorzystać z innego rozwiązania.
Metoda 3: NewOCR
Całkowicie bezpłatna usługa OCR, która pozwala wyodrębnić tekst z praktycznie dowolnych dokumentów graficznych i elektronicznych, takich jak DjVu i PDF. Zasób nie narzuca ograniczeń dotyczących rozmiaru i liczby rozpoznawalnych plików, nie wymaga rejestracji i oferuje szeroki zakres powiązanych funkcji.
NewOCR obsługuje 106 języków i jest w stanie poprawnie obsługiwać nawet skanowanie dokumentów o niskiej jakości. Możliwe jest ręczne wybranie obszaru do rozpoznawania tekstu na stronie pliku.
- Możesz więc natychmiast rozpocząć pracę z zasobem, bez konieczności wykonywania niepotrzebnych czynności.
![Pobieranie pliku PDF rozpoznawania do usługi online NewOCR]()
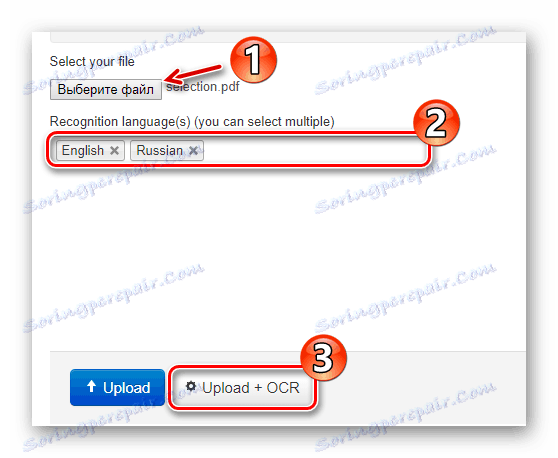
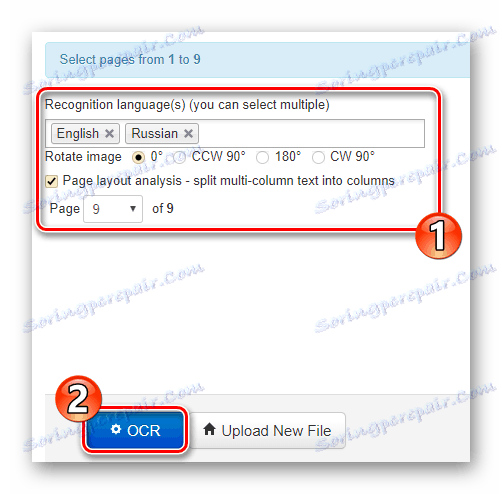
Bezpośrednio na stronie głównej znajduje się formularz do importowania dokumentu do serwisu. Aby przesłać plik do NewOCR, użyj przycisku "Wybierz plik" w sekcji "Wybierz plik" . Następnie w polu "Języki uznania" wybierz jeden lub więcej języków oryginalnego dokumentu, a następnie kliknij "Prześlij + OCR" . - Ustaw preferowane ustawienia rozpoznawania, wybierz żądaną stronę, aby wyodrębnić tekst i kliknij przycisk "OCR" .
![Konfigurowanie i uruchamianie rozpoznawania tekstu z pliku PDF w serwisie online NewOCR]()
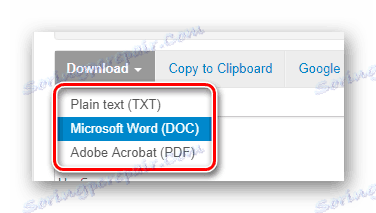
- Przewiń nieco poniżej i znajdź przycisk "Pobierz" .
![Pobierz tekst wyodrębniony do NewOCR na komputer]()
Kliknij na niego i wybierz wymagany format dokumentu do pobrania z rozwijanej listy. Następnie gotowy plik z wyodrębnionym tekstem zostanie pobrany na twój komputer.
Narzędzie jest wygodne i rozpoznaje wszystkie postacie w wystarczająco wysokiej jakości. Jednak przetwarzanie każdej strony zaimportowanego dokumentu PDF musi zostać uruchomione niezależnie i wyświetlone w oddzielnym pliku. Możesz, oczywiście, natychmiast skopiować wyniki rozpoznawania do schowka i połączyć je z innymi.
Niemniej jednak, biorąc pod uwagę powyższy niuans, duże ilości tekstu za pomocą NewOCR są bardzo trudne do wyodrębnienia. Usługa radzi sobie z małymi plikami "z hukiem".
Metoda 4: OCR.Space
Proste i zrozumiałe źródło do digitalizacji tekstu pozwala rozpoznać dokumenty PDF i wyprowadzić wynik do pliku TXT. Nie ma ograniczeń co do liczby stron. Jedynym ograniczeniem jest to, że rozmiar dokumentu wejściowego nie powinien przekraczać 5 megabajtów.
- Rejestracja do pracy z narzędziem nie jest konieczna.
![Zaimportuj plik PDF do usługi online OCR.Space]()
Po prostu kliknij powyższy link i prześlij dokument PDF do witryny ze swojego komputera za pomocą przycisku "Wybierz plik" lub z sieci, klikając łącze. - W rozwijanym menu "Wybierz język OCR" wybierz język importowanego dokumentu.
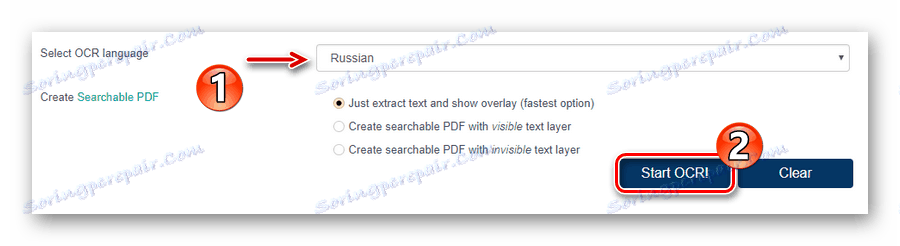
![Rozpoczęcie procesu rozpoznawania dokumentu PDF w usłudze online OCR.Space]()
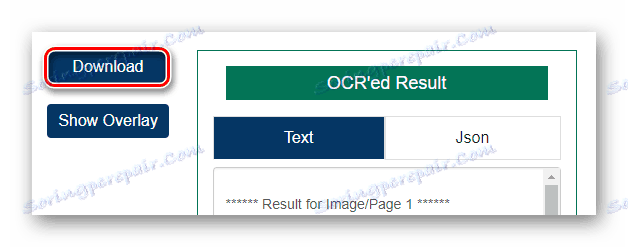
Następnie rozpocznij proces rozpoznawania tekstu, klikając przycisk "Uruchom OCR!" . - Po zakończeniu przetwarzania pliku sprawdź wynik w polu "OCR" Wynik i kliknij "Pobierz", aby pobrać gotowy dokument TXT.
![Pobieranie wyniku rozpoznania pliku PDF z usługi online OCR.Space]()

Jeśli potrzebujesz tylko wyodrębnić tekst z pliku PDF, a ostateczne formatowanie nie jest ważne, OCR.Space to dobry wybór. Jedyny dokument musi być "jednojęzyczny", ponieważ nie zapewnia się uznania dwóch lub więcej języków w tym samym czasie w usłudze.
Zobacz także: Bezpłatne analogi programu FineReader
Oceniając narzędzia online przedstawione w artykule, należy zauważyć, że ABBYY FineReader Online obsługuje funkcję OCR najdokładniej i dokładniej. Jeśli maksymalna dokładność rozpoznawania tekstu jest dla Ciebie ważna, najlepiej rozważyć tę konkretną opcję. Ale aby zapłacić za to, najprawdopodobniej też trzeba.
Jeśli chcesz zdigitalizować małe dokumenty i jesteś gotowy do samodzielnego naprawienia błędów w usłudze, zaleca się użycie funkcji NewOCR, OCR.Space lub Free Online OCR.